参考:知乎专栏-搜索推荐广告排序艺术
搜索推荐广告排序艺术
自监督学习(Self-supervised Learning)属于无监督学习的一种方法,其目的是更好地利用无监督数据,提升后续监督学习任务的效果。
其基本思想是:
- Predicting everything from everything else。
具体方法:
- 定义一个Pretext task (辅助任务),即从无监督的数据中,通过巧妙地设计自动构造出有监督(伪标签)数据,学习一个预训练模型。构造有监督(伪标签)数据的方法可以是:假装输入中的一部分不存在,然后基于其余的部分用模型预测缺失的这部分。如果学习的预训练模型能准确预测缺失部分的数据,说明它的表示学习能力很强,能够学习到输入中的高级语义信息、泛化能力比较强。而深度学习的精髓正在于强大的表示学习能力;
- 将预训练模型通过简单的微调,即可应用到下游的多个应用场景,能获得比只用有监督数据训练的模型更好的效果。
通常来说,有标签数据越少的场景下自监督学习能带来的提升越大。事实上,在一些论文的实验结果里,在大量无标签数据上自监督学习的模型,不需要finetune,能取得比使用标签数据学得的监督模型更好的效果……
对于有大量标签数据的场景,自监督学习也能进一步提升模型的泛化能力和效果。
下图展示了在CV领域自监督学习的标准流程:
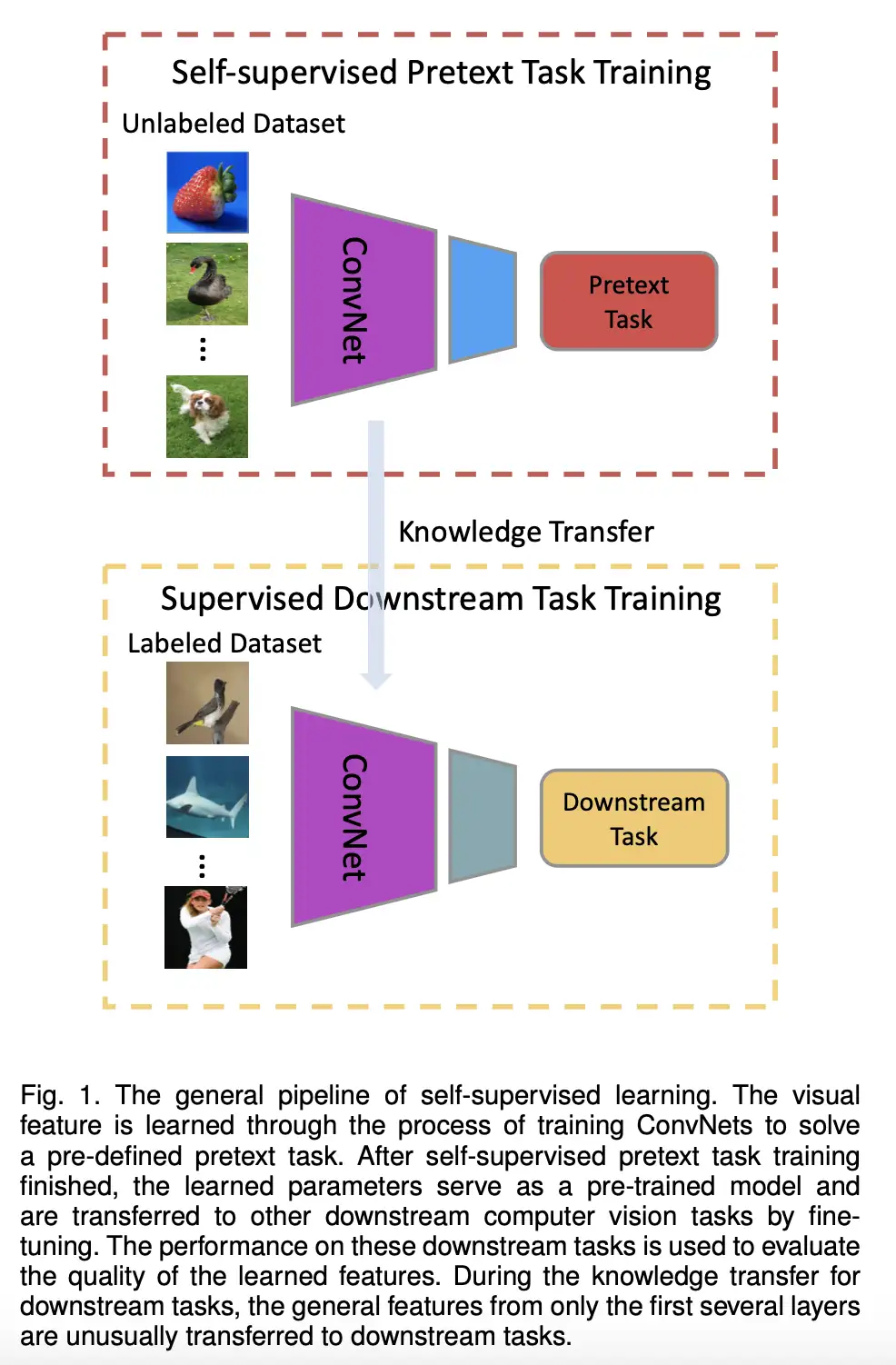
在自监督学习中,最重要的问题是:如何定义Pretext任务、如何从Pretext任务学习预训练模型。